Transformer(Attention Is All You Need)
人工智能的核心思想是来自于2017年8位Google的员工发表的一篇论文 :Attention is all you need,抛弃RNN的循环结构,完全基于自注意力机制捕捉序列中任意两个位置关系,实现并行计算。
1. Transformer之前
在Transformer之前,RNN及其变种LSTM几乎完全统治了自然语言处理,CNN用于图像识别处理
1.1. RNN(Recurrent Neural Network) 循环神经网络
擅长处理序列数据—-文本/音频/时间序列
核心思想:通过记忆前一步的信息来预测下一步的信息,每一步的计算都需要等待上一步完成。
问题一:无法并行计算。 这种顺序依赖的机制导致模型无法并行计算,很难充分利用现代计算机强大的并行处理能力。
问题二:记性不太好。 当句子或文本的长度稍长一些的时候,模型很难有效记住比较早的信息。
其改进版本LSTM没有彻底解决长距离依赖和并行问题。
1.2. CNN(Convolutional Neural Network) 卷积神经网络
擅长处理图像/空间结构数据—-图片识别,就像一个拿着放大镜仔细观察图片的人。
CNN虽然能进行并行计算,但他的视野比较窄,也很难记住全局信息
2. Transformer
Transformer是一个非常重要的深度学习框架,尤其在NLP,LLM,视觉等领域都很核心。
5个核心概念
Token
模型不会直接理解一句话,而是先把文本拆成一个个单位,这些单位叫token。 可以查看字和Token的映射网站,ChatGPT TokenizerEmbedding
token不能直接输入神经网络,所以要先变成向量,这一步叫词嵌入(embedding)Positional Encoding
Transformer本身不像RNN那样天然知道顺序,所以需要额外告诉它:- 第一个词在哪
- 第二个词在哪
- 第三个词在哪 这就是 位置编码。
Self-Attention
这是transformer最核心的部分。意思是:处理某个词时,模型会看句子里其他词,并决定“我该关注谁更多”。Multi-Head Attention
不是只看一种“关注方式”,而是同时从多个角度看。
2.1. 架构图
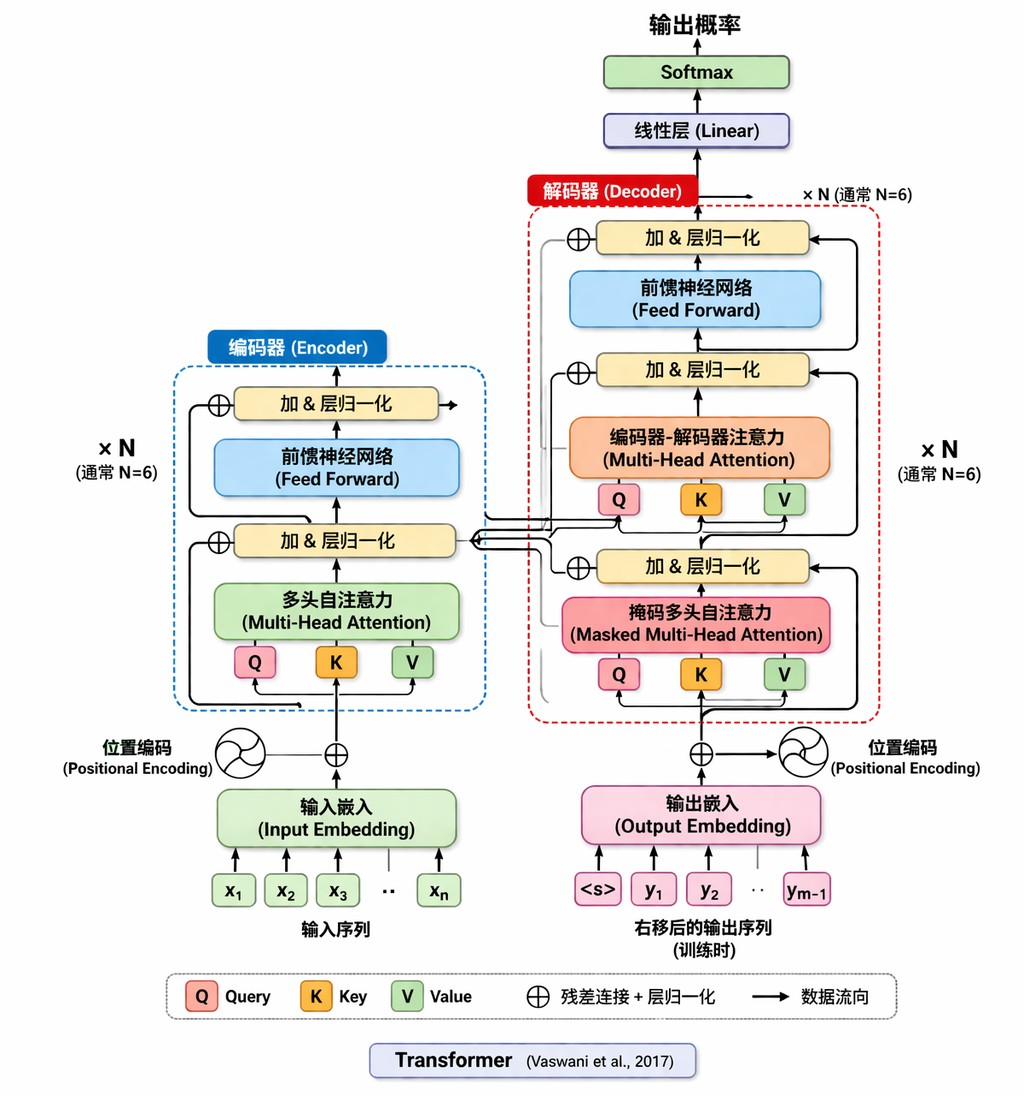
实现并行计算:
- 训练时:一次性输入整个序列,通过矩阵计算所有位置的自注意力。
- 解码阶段:训练时Teacher Forcing并行;推理时自回归逐个生成,但可缓存KV(KV Cache)。
Multi-Head Attention
- 单头注意力可能只关注一种模式(如语法、语义)。
- 多头允许模型从不同子空间(不同表示投影)联合捕获多种特征,类似CNN的多通道。
2.2. 自注意力机制的计算公式
$$ Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V $$
把QKV理解成“查字典”或者“搜索商品”比较好理解。
- Q(Query,查询):就是你的需求。比如你想搜“休闲牛仔裤”,这句话就是Query。
- K(Key,键):每个东西的标签。比如淘宝上每条裤子都有自己的标题、关键词(浅蓝色、休闲、修身等),这些就是Key。
- V(Value,值):实际内容。就是那条裤子的详情页、图片、价格等真实信息。
用Q去和所有K做匹配,算出相似度。匹配度高的,就把它的V重点看;匹配度低的,就少看或不看。最后综合所有V,得出真正关心的结果。
其中除以缩放因子$\sqrt{d_k}$防止点积过大导致softmax梯度消失。假设Q和K是均值为0、方差为1的独立向量,点积结构方差为dk。若不缩放,方差过大导致softmax输出集中在0或1,梯度极小;缩放后方差恢复为1.